Un nouvel acronyme (un de plus !) a le vent en poupe dans l’univers des bibliothèques et plus généralement des institutions patrimoniales : IIIF (prononcer en français « trois-I-F » ou « I-trois-F » !). Il désigne à la fois une communauté et un ensemble de technologies qui sont actuellement en plein essor dans le domaine des bibliothèques numériques.
![]()
Pourquoi IIIF ?
Dans son billet « Données, corpus numérisés et humanités numériques » d’avril 2013, Isabelle Westeel faisait état d’une profusion de ressources numérisées accessibles sur le Web et posait la question de leur impact sur la recherche et les humanités numériques. La question centrale de l’interopérabilité y était clairement soulignée, au même titre que d’autres problématiques clés telles que la visualisation, l’accessibilité et la valorisation de ces contenus. L’initiative IIIF se positionne clairement sur ce terrain et les technologies qu’elle promeut tentent d’y apporter des solutions innovantes.
Si de nombreux schémas et protocoles ont vu le jour afin de répondre aux besoins d’échange et d’agrégation de métadonnées (Dublin Core et OAI-PMH pour n’en citer que deux), les images sont restées les parents pauvres de ces initiatives. Elles ont souvent représenté un fardeau pour les institutions culturelles ou scientifiques engagées dans la numérisation de documents et leur diffusion sur le Web. En effet, la mise en ligne d’images haute résolution est une opération assez complexe et coûteuse, et les briques technologiques qu’elle requiert relativement difficiles à concevoir et à maintenir. Or sur ce plan les bibliothèques numériques ont proliféré sans réelle coordination technique durant ces deux dernières décennies, chaque plateforme ayant presque toujours fait l’objet de développements ad hoc (serveurs d’images, visualiseurs d’images, outils d’annotation etc.). Chacun a beaucoup investi pour développer de son côté des solutions incompatibles les unes avec les autres, mais répondant pourtant à des besoins communs. Les fruits de ces efforts demeurent donc difficilement partageables et réutilisables, les outils développés ne sont pas interopérables. Le constat est le même en ce qui concerne les contenus numérisés : ceux-ci ne sont consultables que sur le site de la bibliothèque numérique d’origine, ils sont comme emprisonnés dans les dispositifs techniques qui permettent d’y accéder. La logique de silos a prévalu. Cette situation est aujourd’hui perçue comme un frein à la réutilisation et à l’émergence de nouveaux usages autour de ces contenus dans l’environnement numérique.
C’est de ce constat qu’est né le besoin de standardisation, et donc de collaboration, autour duquel s’est constituée l’initiative IIIF. Et c’est à ces problématiques que répondent les standards et outils mis au point par cette communauté. Ce mouvement s’inscrit pleinement dans la logique de décloisonnement des silos et dans le « modèle de mutualisation » décrit par Figoblog dans son billet « L’évolution du modèle d’agrégation de données dans les bibliothèques numériques »1, particulièrement du point de vue des outils (infrastructure technique) et des contenus.
Qu’est-ce que IIIF ?
IIIF (International Image Interoperability Framework) est un ensemble de standards dont l’objectif est de définir un cadre d’interopérabilité pour les bibliothèques numériques.
Il est porté et animé par une communauté constituée pour l’essentiel de bibliothèques nationales, de musées, d’universités, d’agrégateurs (Artstor, Europeana, DPLA) et de projets plus ciblés (Biblissima, e-codices, TextGrid…). Des entreprises privées sont aussi directement impliquées dans le processus d’élaboration des spécifications techniques et dans le développement des outils qui les implémentent. Cette communauté est en pleine expansion (plus de 70 établissements/projets participants). Elle s’est constituée depuis juin 2015 en un consortium international d’institutions scientifiques et patrimoniales qui sont parmi les plus gros fournisseurs d’images numériques sur le Web (la BnF en est un des membres fondateurs, il regroupe à ce jour 39 institutions).
Le but de IIIF est de créer un cadre technique commun grâce auquel les bibliothèques numériques peuvent délivrer leurs contenus de manière standardisée sur le Web afin de les rendre consultables, manipulables et annotables par n’importe quelle application ou logiciel compatible. Ainsi chaque entrepôt d’images devient potentiellement un point d’accès distant pour des applications tierces qui vont pouvoir « se brancher » sur ce dernier et réutiliser les images à d’autres fins (comparaison d’images issues de différentes bibliothèques, annotations, conception d’expositions virtuelles etc.). Cette mise en interopérabilité des entrepôts d’images repose sur des spécifications qui définissent des API ou « web services » élaborés de manière concertée au sein de la communauté IIIF. Ces dispositifs permettent par exemple la communication et l’échange à distance d’images numériques entre différents entrepôts à travers le Web, indépendemment du type de document concerné (livres, photographies, journaux, manuscrits, cartes, rouleaux, partitions, objets de musée, etc.).
Ce cadre technique est évolutif, il se compose actuellement :
- d’un modèle de données : Shared Canvas (http://iiif.io/model/shared-canvas/1.0/)
- de 4 APIs fonctionnant de manière conjointe et complémentaire :
- API Image : http://iiif.io/api/image
- API Presentation : http://iiif.io/api/presentation
- API « Content Search » : http://iiif.io/api/search
- API Authentification : http://iiif.io/api/auth/0.9/ (draft)
Afin de ne pas surcharger ce billet, et pour ne pas avoir à entrer dans des considérations trop techniques, nous nous focaliserons sur les 2 APIs principales de IIIF : l’API Image et l’API Presentation.
L’API Image
La spécification « Image API » définit une syntaxe d’URL standardisée permettant de manipuler une image à distance au moyen de paramètres de région, de taille, de rotation, de qualité et de format. Par exemple, il est possible de requêter une image pleine taille, de faire pivoter, de redimensionner ou recadrer une image entière ou une partie de cette image.
Modèle de requête d’image IIIF :
http(s)://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}
Les fonctionnalités de l’API Image sont exploitées notamment par des visualiseurs d’images haute résolution capables de proposer un zoom profond et progressif, comme dans l’exemple ci-dessous (les images affichées sont appelées directement depuis Gallica grâce à l’API Image de IIIF) :
– Tétradrachme de Clazomènes (Ionie, vers 380 av.J.-C). BnF, département des Monnaies, médailles et antiques, Luynes 2582 (voir sur Gallica / en savoir plus : droit ; revers)
– Eucratidion, atelier de Eucratide Ier le Grand (Bactriane, vers 170-vers 145 av. J.-C). BnF, département des Monnaies, médailles et antiques, E 3605 (voir sur Gallica / en savoir plus : droit / revers).
L’API Image offre donc un mécanisme simple pour appeler et manipuler de manière dynamique une image numérique. Elle sert de socle commun au développement d’outils exploitant les images (essentiellement des serveurs et visualiseurs d’images). En rendant adressable des zones au sein d’une image, elle permet aussi à un internaute de citer sur le Web des régions d’intérêt afin de mettre en lumière tel ou tel détail de l’image (exemple).

Monogramme de l’Eucratidion (http://gallica.bnf.fr/iiif/ark:/12148/btv1b8510709q/f2/2244,2109,274,301/,250/0/grey.jpg)
L’API Presentation
La spécification « Presentation API » décrit un service web destiné à délivrer de manière standardisée des informations de présentation et de structure d’un objet numérique. Il s’agit d’exposer sur le Web les métadonnées nécessaires au rendu de cet objet dans une interface (en premier lieu un visualiseur d’images, ou tout autre environnement de travail mobilisant des images). Ces « métadonnées » sont à distinguer des métadonnées documentaires, elles ne sont pas orientées vers la recherche de documents au sein d’une collection ou d’un corpus : elles sont à envisager uniquement du point de vue du rendu d’un objet numérisé et dans l’optique d’enrichir l’expérience utilisateur.
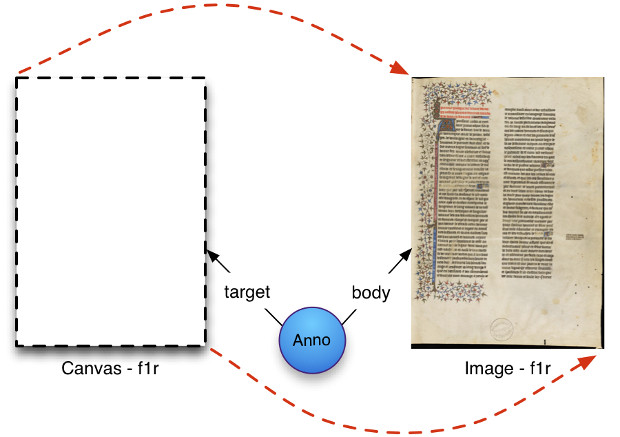
Toutes ces informations sont embarquées dans un fichier appelé « manifeste IIIF », qui peut représenter tout type d’objets numériques (fac-similé numérique d’objet physique ou objet composite nativement numérique, par exemple un livre imprimé ou un manuscrit, une photographie, un journal, un objet muséal etc.). Le manifeste2 permet de décrire la structure interne de l’objet numérique, du point de vue intellectuel ou matériel : succession de chapitres dans un livre ou d’articles dans un journal, structure codicologique d’un manuscrit etc. Le manifeste contient aussi une ou plusieurs séquences de canevas, c’est-à-dire la liste ordonnée des pages, vues ou surfaces qui composent l’objet. Typiquement, dans le cas d’un livre numérisé, à chaque page correspondra un canevas.
Le canevas est un concept introduit par le modèle Shared Canvas, fondé sur le paradigme de l’annotation. Le canevas est conçu comme un espace vide représentant de manière abstraite une page (s’il s’agit d’un livre) ou une vue particulière d’un objet numérisé. Il va servir de réceptacle à toutes sortes de ressources numériques conçues comme des annotations sur ce même canevas. Le principe est assez similaire à une diapositive dans une présentation PowerPoint. Ainsi l’image numérique d’une page est conçue comme une annotation sur un canevas, au même titre que n’importe quel contenu numérique que l’on souhaiterait associer à cette même page : on peut penser à la transcription du texte inscrit sur la page (issue d’une opération manuelle ou d’un processus automatique de reconnaissance optique de caractères), la traduction de ce texte, des tags ou des commentaires d’utilisateurs, voire des ressources audio ou vidéo (par exemple pour écouter l’interprétation d’une partition musicale). Il est ainsi possible d’associer à un canevas plusieurs couches d’annotations de différentes natures ou statuts.
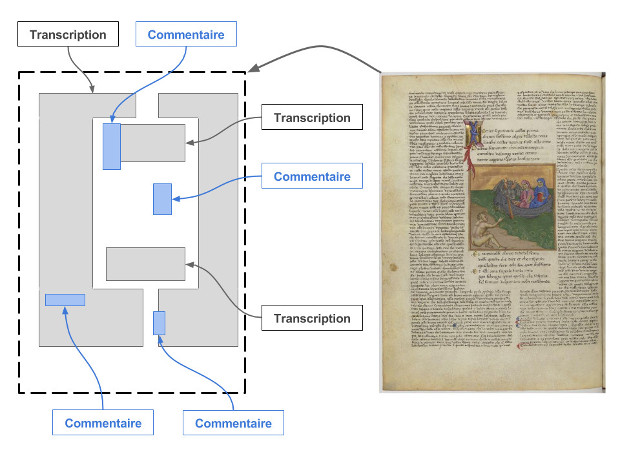
Ce principe du canevas annoté permet aussi de prendre en charge des cas complexes qui interviennent assez fréquemment dans le domaine des manuscrits médiévaux (entre autres) :
- une même page a été numérisée plusieurs fois au fil du temps ou sous différentes conditions de lumière (numérisation du microfilm noir et blanc puis numérisation en couleur à partir du document original ; images multi-spectrales produites pour l’étude scientifique d’un palimpseste par exemple).
- une page mutilée dont les enluminures ont été découpées à un moment donné de l’histoire du document, puis numérisées séparément du manuscrit d’origine (dans ce cas on a l’image de la page mutilée associée au canevas, et l’image de détail associée à une zone de ce canevas, de façon à repositionner l’enluminure à son emplacement originel).
Voir la démo du manuscrit 5 de Châteauroux, « Grandes Chroniques de France » (Biblissima) - une page reconstituée à partir de plusieurs fragments (plusieurs images associées à différentes zones du canevas).
- l’absence de page (cas de lacunes identifiées dans un manuscrit, qui seraient alors représentées dans le manifest par des canevas vides, mais auquels on pourrait quand même associer la transcription du texte le cas échéant, dans le cas où les feuillets auraient été perdus après).
Voir la démo de reconstitution virtuelle d’un manuscrit dispersé, le « Florus dispersus » (Biblissima)
Les fichiers « manifestes » encapsulent donc toutes ces données de structure et de présentation : séquence ordonnée de canevas, annotations de type image ou potentiellement d’une autre nature (texte, son, vidéo). Ils contiennent aussi des informations descriptives nécessaires à la compréhension de l’objet représenté (nature, contexte, provenance etc.).
Bref aperçu des visualiseurs d’images
Les manifestes sont avant tout destinés à être « consommés » par des visualiseurs d’images compatibles avec IIIF. Ces applications commencent par charger à distance le manifeste puis utilisent les informations qu’il contient pour recomposer dynamiquement l’objet numérique dans une interface web riche. Il existe plusieurs visualiseurs ou clients d’images qui supportent les deux API Image et Presentation. Parmi eux, Mirador et Universal Viewer sont les plus perfectionnés. Sans entrer dans le détail des fonctionnalités supportées par l’un ou par l’autre, notons simplement la plus marquante ou celle qui constitue leur principal atout respectif :
Universal Viewer propose une fonction de recherche dans les annotations associées à un document (que celles-ci aient été générées automatiquement par OCR ou créées manuellement par des utilisateurs). Elle permet par exemple de rechercher un terme dans le texte intégral d’un document « océrisé » et de surligner les résultats au bon endroit dans chacune des images (voir un exemple). Cette fonctionnalité repose sur la troisième API de IIIF intitulée « Content Search« , dont il n’a pas été question dans ce billet.
Mirador offre quant à lui une interface multi-fenêtres qui permet d’afficher plusieurs documents dans un même espace de travail configurable. Ainsi l’utilisateur peut charger les documents qui l’intéresse, les comparer côte à côte, puis ajouter un nouveau document dans une troisième fenêtre, en retirer un, changer la disposition des fenêtres etc… Il peut donc composer son environnement de visualisation à sa guise et constituer sa propre collection de documents, indépendamment de leur bibliothèque numérique d’origine. C’est bien sûr ce qui fait tout l’attrait des technologies IIIF et rend cette fonctionnalité de Mirador d’autant plus intéressante (toutes les images restent physiquement hébergées sur les serveurs des fournisseurs de contenus). Pouvoir comparer un manuscrit de Harvard et un manuscrit de la BnF en quelques clics − sans avoir à télécharger les images − et les inspecter en détail grâce au zoom, et même les annoter, sont autant de possibilités nouvelles qui ont longtemps été un rêve pour les chercheurs.
Démo
Rien ne vaut une petite démo pour illustrer ces fonctionnalités novatrices et commencer à manipuler un outil comme Mirador : la démo proposée ci-dessous rassemble à titre d’exemple une petite collection de documents contenant des représentations de la ville d’Athènes et de l’Acropole dans des peintures, dessins et photographies anciennes des 18e, 19e et début du 20e siècles :
 Voir la démo du visualiseur Mirador
Voir la démo du visualiseur Mirador
Sélection de peintures, dessins et photographies anciennes représentant la ville d’Athènes et l’Acropole en particulier (18e, 19e et début du 20e siècle), provenant de 6 institutions différentes à travers le monde (bibliothèques et musées).
Un autre exemple montre deux monnaies athéniennes, un tétradrachme d’argent d’un côté (conservé au Harvard Art Museums) et un statère d’or de l’autre (conservé au département des Monnaies, Médailles et Antiques de la BnF): voir la démo.
Avantages et perspectives
Comme nous venons de le voir à travers les démos, les deux principales APIs de IIIF permettent une expérience de visualisation des images plus riche et plus fluide tout en ouvrant de nouvelles possibilités : inspecter en détail, comparer, citer et partager, annoter, créer des « mash-up » (application composite).
Les standards IIIF forment un socle technique commun qui favorise le développement d’un écosystème applicatif autour des images numériques. Pour les institutions qui mettent en ligne des collections numérisées, cela présente un certain nombre d’avantages :
- économiques tout d’abord : le coût des développements informatiques est en partie partagé au sein de la communauté IIIF (beaucoup de logiciels sont développés de façon communautaire et distribués en open source).
- en terme de flexibilité : la dépendance à un outil ou logiciel spécifique est moindre et l’éventail des choix possibles est plus large. Il est aussi plus facile de changer d’outil et de choisir le meilleur dans sa catégorie.
- en terme d’interopérabilité et de réutilisation des données : les standards IIIF augmentent le potentiel des contenus des bibliothèques numériques en favorisant leur intégration dans d’autres applications ou pour d’autres usages. Ils démultiplient les possibilités de dissémination et de réutilisation des images sur le Web, tout en permettant à leurs fournisseurs de conserver la trace des flux d’audience (les statistiques de consultation restent comptabilisées sur le site d’origine). Comme le souligne E. Bermès dans son billet, cette interopérabilité est porteuse de nouvelles promesses, comme celle de faciliter la constitution de « bibliothèques numériques de niche, agrégeant et éditorialisant des contenus sélectionnés à un niveau local ». Pensons ici à la création d’expositions virtuelles, à la reconstitution virtuelle de bibliothèques ou collections anciennes aujourd’hui dispersées (Bibliothèque Virtuelle du Mont-Saint-Michel), ou encore à la constitution de corpus numériques spécialisés (projet Roman de la Rose((Roman de la Rose Digital Library : http://romandelarose.org))).
De plus, les annotations présentent un fort potentiel d’enrichissement et de mise en relation des contenus. Avec IIIF, tout devient annotable. Au sein d’une institution, les annotations peuvent servir à améliorer les contenus à la source, par exemple pour rendre plus performante le moteur de recherche : indexation manuelle ou automatisée du contenu des images, océrisation du texte etc. Pour peu que les contenus soient librement accessibles sur le Web, quiconque peut également les annoter à l’extérieur de l’institution, pour ses propres besoins, ou au profit de l’institution dans le cas d’un projet de crowdsourcing par exemple : créer un lien vers une autre ressource, transcrire ou traduire le texte, identifier une personne ou un lieu dans l’image, laisser une note ou un commentaire personnel etc. Les possibilités sont innombrables.
Conclusion
Les technologies IIIF ouvrent donc de nouveaux horizons pour la valorisation du patrimoine culturel numérisé et son usage à des fins d’enseignement et de recherche, le tout dans un environnement décentralisé par nature. Elles sont en voie de s’imposer comme des standards incontournables dans le monde des bibliothèques numériques. Un nombre croissant de logiciels et plateformes web les proposent de manière native (outils libres développés au sein de la communauté, et solutions logicielles d’éditeurs commerciaux).
La communauté IIIF s’élargit et devient de plus en plus foisonnante. Elle se structure et se diversifie aussi : des groupes de travail ou d’intérêt centrés sur un domaine, une pratique ou un type de contenus se sont constitués dans le courant de l’année 2016 (manuscrits, journaux, musées, développeurs, audio/vidéo). D’autres sont en gestation (archives), et des rapprochements avec d’autres communautés sont déjà engagés (Web, Open Annotation, TEI, Digital Humanities…). L’extension de IIIF aux contenus audio/vidéo est également un des chantiers en cours.
En France, l’initiative IIIF commence à faire parler d’elle et ses standards ont d’ores et déjà été adoptés par une poignée de projets ou institutions (ou sont en voie de l’être). La Bibliothèque nationale de France a été pionnière en implémentant l’API Image dans Gallica dès 2014, puis l’API Presentation l’année suivante. L’Equipex Biblissima joue aussi un rôle moteur et est activement impliqué dans la communauté IIIF depuis les débuts du projet en 2013.
Régis Robineau
Pour aller plus loin :
Site officiel de l’initiative IIIF : http://iiif.io
Site officiel de Mirador : http://projectmirador.org
Introduction à IIIF (en français) sur le site de documentation de Biblissima : http://doc.biblissima-condorcet.fr/introduction-iiif
Voir aussi la page sur les entrepôts d’images compatibles IIIF situés dans le périmètre de Biblissima : http://doc.biblissima-condorcet.fr/entrepots-iiif-biblissima
Introduction à IIIF, présentation lors de la journée « Linked Data et interopérabilité des images sur le Web » (MAE, Nanterre, 8 avril 2016), par Régis Robineau : http://www.biblissima-condorcet.fr/fr/introduction-a-iiif
Liste de liens utiles sur IIIF : https://github.com/IIIF/awesome-iiif
- Emmanuelle Bermès, « L’évolution du modèle d’agrégation de données dans les bibliothèques numériques ». Disponible sur Figoblog : https://figoblog.org/2016/03/25/levolution-du-modele-dagregation/ [↩]
- En informatique, un « manifeste » désigne un fichier qui liste toutes sortes d’informations relatives à une application : par exemple la liste des fichiers qui la composent, diverses métadonnées telles que le nom de l’application, son auteur, le numéro de version etc. Le terme est emprunté au vocabulaire maritime et désigne un « document obligatoire donnant un état général du chargement composant la cargaison d’un navire ou d’un avion et qui doit être remis à la douane avant le déchargement » (source : CNRTL). [↩]
Lire aussi sur Insula :
Régis Robineau, « Comprendre IIIF et l’interopérabilité des bibliothèques numériques », Insula [En ligne], ISSN 2427-8297, mis en ligne le 8 novembre 2016. URL : <https://insula.univ-lille.fr/2016/11/08/comprendre-iiif-interoperabilite-bibliotheques-numeriques/>. Consulté le 2 March 2026.
Pingback : Comprendre IIIF et l’interopérabil...
Pingback : Comprendre IIIF et l’interopérabil...
Pingback : Mautima Alcuri (maudrival) | Pearltrees
Pingback : Comprendre IIIF et l’interopérabil...